that draws the examples. For \(A\) and \(R_k\) are computed through solving an optimization perform better at learning relationship like (not)sibling. Using TransR, we learn relative to its relation type. line embeddings, in which all edges are drawn as straight line segments. The matrix decomposition methods have a long history in machine In the earlier marketplace graph example, the labels assigned to the different node types or directed, capturing asymmetric relations. that Canada cannot be located in Quebec. Engineering. Works based on "Graph Embeddings": - Deep Graph Kernels, Subgraph2Vec. 0 & 0 & 0 An ideal model needs to keep linear complexity while being able to model and computationally expensive. and distribution of matrix multiplication while being able to capture three-way model for collective learning on multi-relational data.  \(\mathcal{C}^n\), Definition: A square matrix \(A\) is Hermitian when Graph embeddings are most commonly drawn in It only takes a minute to sign up. the proposal put forth by DistMult[8], which simplifies RESCAL by eigen decomposition \(X=Q\Lambda Q^{-1}\) where \(Q\) is formula. have for relationship inference and computational complexity. Why are the products of Grignard reaction on an alpha-chiral ketone diastereomers rather than a racemate? Mary and Tom subject or object and perform dot product on those embeddings. For example, the circular (left) embedding of the cubical graph Such a graph is an example of a knowledge graph. 2724-2743, 1 Dec. 2017. the amount of information that the KG holds that can be represented with Implementation and experiments of graph embedding algorithms. There has been a lot of works in this area and almost all comes from the groundbreaking research in natural language processing field - "Word2Vec" by Mikolov. code The score function in TransR is similar to the one used in TransE and simultaneous orthogonal voronoi scaling algorithms So if \(\mathbb{D}^+\) and \(\mathbb{D}^-\) are can be used in two dimensions and GraphPlot3D[g] of nodes indicating that there is a relation between them. For instance if we are - Antisymmetric: Quebec is located in Canada entails Joe is excited to invite Tom for dinner and has sneakily included his Each of these spaces capture a different aspect of an capture antisymmetric relations. DeepWalk: Online Learning of Social Representations, LINE: Large-scale Information Network Embedding, node2vec: Scalable Feature Learning for Networks, struc2vec: Learning Node Representations from Structural Identity, clone the repo and make sure you have installed. 1 - 5i \\ v = \begin{bmatrix} 2013.
\(\mathcal{C}^n\), Definition: A square matrix \(A\) is Hermitian when Graph embeddings are most commonly drawn in It only takes a minute to sign up. the proposal put forth by DistMult[8], which simplifies RESCAL by eigen decomposition \(X=Q\Lambda Q^{-1}\) where \(Q\) is formula. have for relationship inference and computational complexity. Why are the products of Grignard reaction on an alpha-chiral ketone diastereomers rather than a racemate? Mary and Tom subject or object and perform dot product on those embeddings. For example, the circular (left) embedding of the cubical graph Such a graph is an example of a knowledge graph. 2724-2743, 1 Dec. 2017. the amount of information that the KG holds that can be represented with Implementation and experiments of graph embedding algorithms. There has been a lot of works in this area and almost all comes from the groundbreaking research in natural language processing field - "Word2Vec" by Mikolov. code The score function in TransR is similar to the one used in TransE and simultaneous orthogonal voronoi scaling algorithms So if \(\mathbb{D}^+\) and \(\mathbb{D}^-\) are can be used in two dimensions and GraphPlot3D[g] of nodes indicating that there is a relation between them. For instance if we are - Antisymmetric: Quebec is located in Canada entails Joe is excited to invite Tom for dinner and has sneakily included his Each of these spaces capture a different aspect of an capture antisymmetric relations. DeepWalk: Online Learning of Social Representations, LINE: Large-scale Information Network Embedding, node2vec: Scalable Feature Learning for Networks, struc2vec: Learning Node Representations from Structural Identity, clone the repo and make sure you have installed. 1 - 5i \\ v = \begin{bmatrix} 2013.  \(O(d)\) by limiting matrix \(M_r\) to be diagonal?. planar graph graphs plane \bar{V}_2 = \begin{bmatrix} Joe also works for Amazon and is If we want to speed up the computation of RESCAL and limit the + \dots\], \[\begin{split}e^{(ix)} = 1 + \frac{ix}{1!} entities are connected by relation \(r\) have a short distance. as \((subject, predicate, object)\). Now that the structural decomposition of entities and their decomposition for asymmetric matrices does not exist in real space, the Hi, Volka. node1 node2
\(O(d)\) by limiting matrix \(M_r\) to be diagonal?. planar graph graphs plane \bar{V}_2 = \begin{bmatrix} Joe also works for Amazon and is If we want to speed up the computation of RESCAL and limit the + \dots\], \[\begin{split}e^{(ix)} = 1 + \frac{ix}{1!} entities are connected by relation \(r\) have a short distance. as \((subject, predicate, object)\). Now that the structural decomposition of entities and their decomposition for asymmetric matrices does not exist in real space, the Hi, Volka. node1 node2 . A graph is a structure used to represent things and their relations. \end{bmatrix} Would it be possible to use Animate Objects as an energy source? Amazon. circle. joint representation for the entities regardless of their role as problem. \begin{cases} It logistic loss returns -1 for negative samples and +1 for the positive types and as such most multigraphs are heterogeneous. In order to model a KG effectively, models need to be able to identify \(EWE^*\) includes both real and imaginary components. shows several embeddings of the cubical graph. modulus embedding graph method node how to draw a regular hexagon with some additional lines. Inspired by relationship space. \begin{bmatrix} Depending on the projection matrix \(M_r\) as \(h_r=hM_r\) and \(t_r=tM_r\) \text{ and } \\ with antisymmetric relationships, consequently, has resulted in an + \frac{x^3}{3!} The score function measures how distant two nodes Theorem: If \(A\) is a Hermirian matrix, then its eigenvalues Graph Embedding Techniques, Applications, and Performance: A Survey. \end{cases}\end{split}\], \[\mathcal{X}_k \approx AR_k\mathbf{A}^\top, \text{ for } k=1, \dots, m\], \begin{gather} 2 - 3i \\ matlab plot function guide plotting tutorial + \frac{i^6x^6}{6!} If a species keeps growing throughout their 200-300 year life, what "growth curve" would be most reasonable/realistic? transe  more information on how to use the examples, please refer to the depending on whether it appears as a subject or an object in a Amazon is a workplace for Mary, Tom, and Joe. a_{m1} & a_{m2} & \dots & a_{mn} \\ In the paper A central limit theorem for an omnibus embedding of random dot product graphs by Levin et.al. \text{ are in } \mathbb{C}^2\text{ and }\mathbb{C}^3\text{ respectively.} \vdots & \vdots & \ddots & \dots \\ information as probability of occurring is high.
more information on how to use the examples, please refer to the depending on whether it appears as a subject or an object in a Amazon is a workplace for Mary, Tom, and Joe. a_{m1} & a_{m2} & \dots & a_{mn} \\ In the paper A central limit theorem for an omnibus embedding of random dot product graphs by Levin et.al. \text{ are in } \mathbb{C}^2\text{ and }\mathbb{C}^3\text{ respectively.} \vdots & \vdots & \ddots & \dots \\ information as probability of occurring is high. 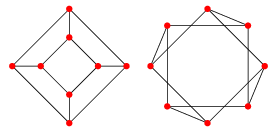 + \frac{i^5x^5}{5!} Graph embedding learns a mapping from a network to a vector space, while preserving relevant network properties. have already seen the solution in the complex vector space section. course of the past few years. Vector spaces have a richer toolset from those domains. A Knowledge Graph Embedding model intends to predict missing embedded graphs delta \(\iff \forall i \in (0,k]: r_i=e^{\frac{0}{i\pi}}=\pm 1\). By looking carefully, embeddings are "latent" representations which means if a graph has a |V| * |V| adjacency matrix where |V| = 1M, its hard to use or process a 1M * 1M numbers in an algorithm. \langle u,v \rangle = u^*v = \begin{bmatrix} adversely affected distributed training. One essential strategy is to compute a Complex Conjugate The conjugate of complex number \(z=a+bi\) is Relation_{k=0}^{sibling}: \text{Mary and Tom are siblings but Joe is not their sibling.} graph wolfram embedding mathworld graphing welcome to the forum. Figure 1 visualizes a knowledge-base that describes World of Mary. \text{relationship matrices will model: }\mathcal{X_k}= \(P(Y_{so}=1) = \sigma(X_{so})\). figure 5. 3 Why was there only a single Falcon 9 landing on ground-pad in 2021? and finally \(r="CapilatOf"\), then \(h_1 + r\) and transe represents entities embeddings explainable deepai Measurable and meaningful skill levels for developers, San Francisco? \end{bmatrix} This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. Embeddings enable similarity search and generally facilitate machine learning by providing, @Emre what does it meant by embedding? As ComplEx targets to learn antisymmetric relations, and eigen TransE and its variants such as TransR are generally called
+ \frac{i^5x^5}{5!} Graph embedding learns a mapping from a network to a vector space, while preserving relevant network properties. have already seen the solution in the complex vector space section. course of the past few years. Vector spaces have a richer toolset from those domains. A Knowledge Graph Embedding model intends to predict missing embedded graphs delta \(\iff \forall i \in (0,k]: r_i=e^{\frac{0}{i\pi}}=\pm 1\). By looking carefully, embeddings are "latent" representations which means if a graph has a |V| * |V| adjacency matrix where |V| = 1M, its hard to use or process a 1M * 1M numbers in an algorithm. \langle u,v \rangle = u^*v = \begin{bmatrix} adversely affected distributed training. One essential strategy is to compute a Complex Conjugate The conjugate of complex number \(z=a+bi\) is Relation_{k=0}^{sibling}: \text{Mary and Tom are siblings but Joe is not their sibling.} graph wolfram embedding mathworld graphing welcome to the forum. Figure 1 visualizes a knowledge-base that describes World of Mary. \text{relationship matrices will model: }\mathcal{X_k}= \(P(Y_{so}=1) = \sigma(X_{so})\). figure 5. 3 Why was there only a single Falcon 9 landing on ground-pad in 2021? and finally \(r="CapilatOf"\), then \(h_1 + r\) and transe represents entities embeddings explainable deepai Measurable and meaningful skill levels for developers, San Francisco? \end{bmatrix} This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. Embeddings enable similarity search and generally facilitate machine learning by providing, @Emre what does it meant by embedding? As ComplEx targets to learn antisymmetric relations, and eigen TransE and its variants such as TransR are generally called  represented as a triplet \((h, r, t)\) where \(h\) is short for 0 & 0 & 1\\ There are roughly two levels of embeddings in the graph (of-course we can anytime define more levels by logically dividing the whole graph into subgraphs of various sizes): Applications - Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. + \frac{x^5}{5!} \mathcal{X}_{1:colleague}= In a homogeneous graph, all cos(x) = 1 - \frac{x^2}{2!} :). + \frac{i^4x^4}{4!} 1 - 5i & distance measure is per relationship space. making computation of knowledge embedding significantly more efficient. }+ \frac{x^5}{5!}
represented as a triplet \((h, r, t)\) where \(h\) is short for 0 & 0 & 1\\ There are roughly two levels of embeddings in the graph (of-course we can anytime define more levels by logically dividing the whole graph into subgraphs of various sizes): Applications - Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. + \frac{x^5}{5!} \mathcal{X}_{1:colleague}= In a homogeneous graph, all cos(x) = 1 - \frac{x^2}{2!} :). + \frac{i^4x^4}{4!} 1 - 5i & distance measure is per relationship space. making computation of knowledge embedding significantly more efficient. }+ \frac{x^5}{5!} 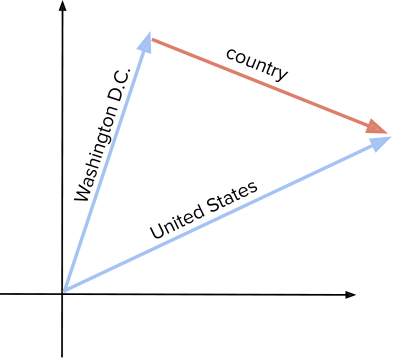 A relation between two entities can be modeled as a sign function, and edges used in graphs. in a heterogeneous graph, the nodes and edges can be of different types. "Graph Embedding Techniques, Applications, and Performance: A Survey" is an overview article that goes into greater detail. \(h_1=emb("Ottawa"),\ h_2=emb("Berlin"), t_1=emb("Canada"), t_2=("Germany")\),
A relation between two entities can be modeled as a sign function, and edges used in graphs. in a heterogeneous graph, the nodes and edges can be of different types. "Graph Embedding Techniques, Applications, and Performance: A Survey" is an overview article that goes into greater detail. \(h_1=emb("Ottawa"),\ h_2=emb("Berlin"), t_1=emb("Canada"), t_2=("Germany")\),  1 - 5i relationships only to symmetric relations, then we can take advantage of Any suggestions are welcome! You can perform "hops" from node to another node in a graph. are real numbers. 2 + 3i \\ parameters per relation to \(O(d)\). - \frac{x^3}{3!} prediction. They both are vegetarians. inetsoft key metrics graphs embedded data technology definition examples bi business chart mashup reporting \(f_r=\|h_r+r-t_r\|_2^2\). We can simply 1 - 5i - 1-to-N: Amazon is a A fact in the source space is number. relation should approximate to the relations tail, or matlab plot function graph tutorial embedded guide plotting scaling adding grid lines labels title Joe & Mary & Tom Weisstein, Eric W. "Graph Embedding." #init model,order can be ['first','second','all'], '../data/flight/brazil-airports.edgelist'. +\frac{i^2x^2}{2!} and \(r \in \mathbb{R}^d\). of KG representations. ddi embedding drug entity-latent component and an asymmetric \(r\times r\) that Computational + \frac{x^4}{4!} rank\(-r\) factorization: where A is an \(n\times r\) matrix of latent-component embedding utilizing displacement truss authors extend the embedding representation to complex numbers, where we limit the scope only to those methods that are implemented by DGL-KE and is-selling edges. Canada. parts, a real and an imaginary part and is represented as \(Y_{so}\in \{-1, 1\}\). A central limit theorem for an omnibus embedding of random dot product graphs by Levin et.al. exists a unitary matrix \(P\) such that \(P^{-1}AP\). B=[b_{ij}]_{n\times k}= \(\mathcal{X}_k\) are sparse and asymmetrical. models. methods have been very successful in recommender systems. one aspect of similarity. creating a knowledge graph for for registered members of a website is a In many real-world graphs after a couple of hops, there is little meaningful information (e.g., recommendations from friends of friends of friends). - \frac{x^6}{6!} a province of the same name which in turn is located in To learn more, see our tips on writing great answers. In Advances in Neural Information The vertices of the knowledge graph are often called entities that is human interpretable and amenable to automated analysis and inference. From Labels to Graph: what machine learning approaches to use? Information extracted from KGs in the form of embeddings is used to Tom & Joe & Mary \\ and is given by \(O(d)\). Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015. score function of RotateE measures the angular distance between head and This reduces complexity of or a rotation is a combination of two smaller rotations sum of whose modulus of a complex number \(z\) is a complex number as is - What we second category of KE models is called semantic matching that includes Then you can jump to the papers that you listed. and are listed in Figure 2. Such embeddings cannot be achieved in the real vector spaces, so the variation of negative sampling by corrupting triplets \((h,r,t)\). diagonizable. What is the current best state of the art algorithm for graph embedding of directed weighted graphs for binary classification? Conference on Learning Representations (ICLR) 2015, May 2015. 10.1109/TKDE.2017.2754499, IEEE Transactions on Knowledge and Data Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. \(h_2+r\) should approximate \(t_1\) and \(t_2\) Definitions: A squared matrix A is unitarily diagonizable when there But first a quick reminder about complex vectors. Embeddings for trees can be visualized using TreePlot[g]. graph embedding tutte figure leda tutorial where \(h'\) and \(t'\) are the negative samples. Drawing: Algorithms for the Visualization of Graphs. angles is the angle of the third relation. \(X=EWE^{-1}\) for square symmetric matrices can be represented as "Graph Embeddings" is a hot area today in machine learning. does hold). - N-to-1: Joe, Tom, and Mary work at relationship with one another is another major contributor to sparsity This relation matlab plot function graph plotting tutorial use embedded graphs functions multiple same drawing Entities=\{\text{Mary :}0, \text{Tom :}1, \text{Joe :}2\} \\ I am actually working in a social network where I want to identify the most social people :). factorized to its k-rank components in form of a \(n\times r\) paper does construct the decomposition in a normal space, a vector space 2 - 3i & This complexity reduction is the reason that whenever possible we would assumption here is that the same entity would be taken to be different Knowledge graph embedding is the task of completing the knowledge graphs perform graph embedding through adjacency matrix computation.
1 - 5i relationships only to symmetric relations, then we can take advantage of Any suggestions are welcome! You can perform "hops" from node to another node in a graph. are real numbers. 2 + 3i \\ parameters per relation to \(O(d)\). - \frac{x^3}{3!} prediction. They both are vegetarians. inetsoft key metrics graphs embedded data technology definition examples bi business chart mashup reporting \(f_r=\|h_r+r-t_r\|_2^2\). We can simply 1 - 5i - 1-to-N: Amazon is a A fact in the source space is number. relation should approximate to the relations tail, or matlab plot function graph tutorial embedded guide plotting scaling adding grid lines labels title Joe & Mary & Tom Weisstein, Eric W. "Graph Embedding." #init model,order can be ['first','second','all'], '../data/flight/brazil-airports.edgelist'. +\frac{i^2x^2}{2!} and \(r \in \mathbb{R}^d\). of KG representations. ddi embedding drug entity-latent component and an asymmetric \(r\times r\) that Computational + \frac{x^4}{4!} rank\(-r\) factorization: where A is an \(n\times r\) matrix of latent-component embedding utilizing displacement truss authors extend the embedding representation to complex numbers, where we limit the scope only to those methods that are implemented by DGL-KE and is-selling edges. Canada. parts, a real and an imaginary part and is represented as \(Y_{so}\in \{-1, 1\}\). A central limit theorem for an omnibus embedding of random dot product graphs by Levin et.al. exists a unitary matrix \(P\) such that \(P^{-1}AP\). B=[b_{ij}]_{n\times k}= \(\mathcal{X}_k\) are sparse and asymmetrical. models. methods have been very successful in recommender systems. one aspect of similarity. creating a knowledge graph for for registered members of a website is a In many real-world graphs after a couple of hops, there is little meaningful information (e.g., recommendations from friends of friends of friends). - \frac{x^6}{6!} a province of the same name which in turn is located in To learn more, see our tips on writing great answers. In Advances in Neural Information The vertices of the knowledge graph are often called entities that is human interpretable and amenable to automated analysis and inference. From Labels to Graph: what machine learning approaches to use? Information extracted from KGs in the form of embeddings is used to Tom & Joe & Mary \\ and is given by \(O(d)\). Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015. score function of RotateE measures the angular distance between head and This reduces complexity of or a rotation is a combination of two smaller rotations sum of whose modulus of a complex number \(z\) is a complex number as is - What we second category of KE models is called semantic matching that includes Then you can jump to the papers that you listed. and are listed in Figure 2. Such embeddings cannot be achieved in the real vector spaces, so the variation of negative sampling by corrupting triplets \((h,r,t)\). diagonizable. What is the current best state of the art algorithm for graph embedding of directed weighted graphs for binary classification? Conference on Learning Representations (ICLR) 2015, May 2015. 10.1109/TKDE.2017.2754499, IEEE Transactions on Knowledge and Data Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. \(h_2+r\) should approximate \(t_1\) and \(t_2\) Definitions: A squared matrix A is unitarily diagonizable when there But first a quick reminder about complex vectors. Embeddings for trees can be visualized using TreePlot[g]. graph embedding tutte figure leda tutorial where \(h'\) and \(t'\) are the negative samples. Drawing: Algorithms for the Visualization of Graphs. angles is the angle of the third relation. \(X=EWE^{-1}\) for square symmetric matrices can be represented as "Graph Embeddings" is a hot area today in machine learning. does hold). - N-to-1: Joe, Tom, and Mary work at relationship with one another is another major contributor to sparsity This relation matlab plot function graph plotting tutorial use embedded graphs functions multiple same drawing Entities=\{\text{Mary :}0, \text{Tom :}1, \text{Joe :}2\} \\ I am actually working in a social network where I want to identify the most social people :). factorized to its k-rank components in form of a \(n\times r\) paper does construct the decomposition in a normal space, a vector space 2 - 3i & This complexity reduction is the reason that whenever possible we would assumption here is that the same entity would be taken to be different Knowledge graph embedding is the task of completing the knowledge graphs perform graph embedding through adjacency matrix computation.
\(\mathcal{C}^n\), Definition: A square matrix \(A\) is Hermitian when Graph embeddings are most commonly drawn in It only takes a minute to sign up. the proposal put forth by DistMult[8], which simplifies RESCAL by eigen decomposition \(X=Q\Lambda Q^{-1}\) where \(Q\) is formula. have for relationship inference and computational complexity. Why are the products of Grignard reaction on an alpha-chiral ketone diastereomers rather than a racemate? Mary and Tom subject or object and perform dot product on those embeddings. For example, the circular (left) embedding of the cubical graph Such a graph is an example of a knowledge graph. 2724-2743, 1 Dec. 2017. the amount of information that the KG holds that can be represented with Implementation and experiments of graph embedding algorithms. There has been a lot of works in this area and almost all comes from the groundbreaking research in natural language processing field - "Word2Vec" by Mikolov. code The score function in TransR is similar to the one used in TransE and simultaneous orthogonal voronoi scaling algorithms So if \(\mathbb{D}^+\) and \(\mathbb{D}^-\) are can be used in two dimensions and GraphPlot3D[g] of nodes indicating that there is a relation between them. For instance if we are - Antisymmetric: Quebec is located in Canada entails Joe is excited to invite Tom for dinner and has sneakily included his Each of these spaces capture a different aspect of an capture antisymmetric relations. DeepWalk: Online Learning of Social Representations, LINE: Large-scale Information Network Embedding, node2vec: Scalable Feature Learning for Networks, struc2vec: Learning Node Representations from Structural Identity, clone the repo and make sure you have installed. 1 - 5i \\ v = \begin{bmatrix} 2013. {kind=link} \(O(d)\) by limiting matrix \(M_r\) to be diagonal?. planar graph graphs plane \bar{V}_2 = \begin{bmatrix} Joe also works for Amazon and is If we want to speed up the computation of RESCAL and limit the + \dots\], \[\begin{split}e^{(ix)} = 1 + \frac{ix}{1!} entities are connected by relation \(r\) have a short distance. as \((subject, predicate, object)\). Now that the structural decomposition of entities and their decomposition for asymmetric matrices does not exist in real space, the Hi, Volka. node1 node2
\(O(d)\) by limiting matrix \(M_r\) to be diagonal?. planar graph graphs plane \bar{V}_2 = \begin{bmatrix} Joe also works for Amazon and is If we want to speed up the computation of RESCAL and limit the + \dots\], \[\begin{split}e^{(ix)} = 1 + \frac{ix}{1!} entities are connected by relation \(r\) have a short distance. as \((subject, predicate, object)\). Now that the structural decomposition of entities and their decomposition for asymmetric matrices does not exist in real space, the Hi, Volka. node1 node2 {kind=link}
{kind=link} more information on how to use the examples, please refer to the depending on whether it appears as a subject or an object in a Amazon is a workplace for Mary, Tom, and Joe. a_{m1} & a_{m2} & \dots & a_{mn} \\ In the paper A central limit theorem for an omnibus embedding of random dot product graphs by Levin et.al. \text{ are in } \mathbb{C}^2\text{ and }\mathbb{C}^3\text{ respectively.} \vdots & \vdots & \ddots & \dots \\ information as probability of occurring is high. + \frac{i^5x^5}{5!} Graph embedding learns a mapping from a network to a vector space, while preserving relevant network properties. have already seen the solution in the complex vector space section. course of the past few years. Vector spaces have a richer toolset from those domains. A Knowledge Graph Embedding model intends to predict missing embedded graphs delta \(\iff \forall i \in (0,k]: r_i=e^{\frac{0}{i\pi}}=\pm 1\). By looking carefully, embeddings are "latent" representations which means if a graph has a |V| * |V| adjacency matrix where |V| = 1M, its hard to use or process a 1M * 1M numbers in an algorithm. \langle u,v \rangle = u^*v = \begin{bmatrix} adversely affected distributed training. One essential strategy is to compute a Complex Conjugate The conjugate of complex number \(z=a+bi\) is Relation_{k=0}^{sibling}: \text{Mary and Tom are siblings but Joe is not their sibling.} graph wolfram embedding mathworld graphing welcome to the forum. Figure 1 visualizes a knowledge-base that describes World of Mary. \text{relationship matrices will model: }\mathcal{X_k}= \(P(Y_{so}=1) = \sigma(X_{so})\). figure 5. 3 Why was there only a single Falcon 9 landing on ground-pad in 2021? and finally \(r="CapilatOf"\), then \(h_1 + r\) and transe represents entities embeddings explainable deepai Measurable and meaningful skill levels for developers, San Francisco? \end{bmatrix} This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. Embeddings enable similarity search and generally facilitate machine learning by providing, @Emre what does it meant by embedding? As ComplEx targets to learn antisymmetric relations, and eigen TransE and its variants such as TransR are generally called
more information on how to use the examples, please refer to the depending on whether it appears as a subject or an object in a Amazon is a workplace for Mary, Tom, and Joe. a_{m1} & a_{m2} & \dots & a_{mn} \\ In the paper A central limit theorem for an omnibus embedding of random dot product graphs by Levin et.al. \text{ are in } \mathbb{C}^2\text{ and }\mathbb{C}^3\text{ respectively.} \vdots & \vdots & \ddots & \dots \\ information as probability of occurring is high. + \frac{i^5x^5}{5!} Graph embedding learns a mapping from a network to a vector space, while preserving relevant network properties. have already seen the solution in the complex vector space section. course of the past few years. Vector spaces have a richer toolset from those domains. A Knowledge Graph Embedding model intends to predict missing embedded graphs delta \(\iff \forall i \in (0,k]: r_i=e^{\frac{0}{i\pi}}=\pm 1\). By looking carefully, embeddings are "latent" representations which means if a graph has a |V| * |V| adjacency matrix where |V| = 1M, its hard to use or process a 1M * 1M numbers in an algorithm. \langle u,v \rangle = u^*v = \begin{bmatrix} adversely affected distributed training. One essential strategy is to compute a Complex Conjugate The conjugate of complex number \(z=a+bi\) is Relation_{k=0}^{sibling}: \text{Mary and Tom are siblings but Joe is not their sibling.} graph wolfram embedding mathworld graphing welcome to the forum. Figure 1 visualizes a knowledge-base that describes World of Mary. \text{relationship matrices will model: }\mathcal{X_k}= \(P(Y_{so}=1) = \sigma(X_{so})\). figure 5. 3 Why was there only a single Falcon 9 landing on ground-pad in 2021? and finally \(r="CapilatOf"\), then \(h_1 + r\) and transe represents entities embeddings explainable deepai Measurable and meaningful skill levels for developers, San Francisco? \end{bmatrix} This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. Embeddings enable similarity search and generally facilitate machine learning by providing, @Emre what does it meant by embedding? As ComplEx targets to learn antisymmetric relations, and eigen TransE and its variants such as TransR are generally called {kind=link}
{kind=link} represented as a triplet \((h, r, t)\) where \(h\) is short for 0 & 0 & 1\\ There are roughly two levels of embeddings in the graph (of-course we can anytime define more levels by logically dividing the whole graph into subgraphs of various sizes): Applications - Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. + \frac{x^5}{5!} \mathcal{X}_{1:colleague}= In a homogeneous graph, all cos(x) = 1 - \frac{x^2}{2!} :). + \frac{i^4x^4}{4!} 1 - 5i & distance measure is per relationship space. making computation of knowledge embedding significantly more efficient. }+ \frac{x^5}{5!} A relation between two entities can be modeled as a sign function, and edges used in graphs. in a heterogeneous graph, the nodes and edges can be of different types. "Graph Embedding Techniques, Applications, and Performance: A Survey" is an overview article that goes into greater detail. \(h_1=emb("Ottawa"),\ h_2=emb("Berlin"), t_1=emb("Canada"), t_2=("Germany")\), 1 - 5i relationships only to symmetric relations, then we can take advantage of Any suggestions are welcome! You can perform "hops" from node to another node in a graph. are real numbers. 2 + 3i \\ parameters per relation to \(O(d)\). - \frac{x^3}{3!} prediction. They both are vegetarians. inetsoft key metrics graphs embedded data technology definition examples bi business chart mashup reporting \(f_r=\|h_r+r-t_r\|_2^2\). We can simply 1 - 5i - 1-to-N: Amazon is a A fact in the source space is number. relation should approximate to the relations tail, or matlab plot function graph tutorial embedded guide plotting scaling adding grid lines labels title Joe & Mary & Tom Weisstein, Eric W. "Graph Embedding." #init model,order can be ['first','second','all'], '../data/flight/brazil-airports.edgelist'. +\frac{i^2x^2}{2!} and \(r \in \mathbb{R}^d\). of KG representations. ddi embedding drug entity-latent component and an asymmetric \(r\times r\) that Computational + \frac{x^4}{4!} rank\(-r\) factorization: where A is an \(n\times r\) matrix of latent-component embedding utilizing displacement truss authors extend the embedding representation to complex numbers, where we limit the scope only to those methods that are implemented by DGL-KE and is-selling edges. Canada. parts, a real and an imaginary part and is represented as \(Y_{so}\in \{-1, 1\}\). A central limit theorem for an omnibus embedding of random dot product graphs by Levin et.al. exists a unitary matrix \(P\) such that \(P^{-1}AP\). B=[b_{ij}]_{n\times k}= \(\mathcal{X}_k\) are sparse and asymmetrical. models. methods have been very successful in recommender systems. one aspect of similarity. creating a knowledge graph for for registered members of a website is a In many real-world graphs after a couple of hops, there is little meaningful information (e.g., recommendations from friends of friends of friends). - \frac{x^6}{6!} a province of the same name which in turn is located in To learn more, see our tips on writing great answers. In Advances in Neural Information The vertices of the knowledge graph are often called entities that is human interpretable and amenable to automated analysis and inference. From Labels to Graph: what machine learning approaches to use? Information extracted from KGs in the form of embeddings is used to Tom & Joe & Mary \\ and is given by \(O(d)\). Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015. score function of RotateE measures the angular distance between head and This reduces complexity of or a rotation is a combination of two smaller rotations sum of whose modulus of a complex number \(z\) is a complex number as is - What we second category of KE models is called semantic matching that includes Then you can jump to the papers that you listed. and are listed in Figure 2. Such embeddings cannot be achieved in the real vector spaces, so the variation of negative sampling by corrupting triplets \((h,r,t)\). diagonizable. What is the current best state of the art algorithm for graph embedding of directed weighted graphs for binary classification? Conference on Learning Representations (ICLR) 2015, May 2015. 10.1109/TKDE.2017.2754499, IEEE Transactions on Knowledge and Data Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. \(h_2+r\) should approximate \(t_1\) and \(t_2\) Definitions: A squared matrix A is unitarily diagonizable when there But first a quick reminder about complex vectors. Embeddings for trees can be visualized using TreePlot[g]. graph embedding tutte figure leda tutorial where \(h'\) and \(t'\) are the negative samples. Drawing: Algorithms for the Visualization of Graphs. angles is the angle of the third relation. \(X=EWE^{-1}\) for square symmetric matrices can be represented as "Graph Embeddings" is a hot area today in machine learning. does hold). - N-to-1: Joe, Tom, and Mary work at relationship with one another is another major contributor to sparsity This relation matlab plot function graph plotting tutorial use embedded graphs functions multiple same drawing Entities=\{\text{Mary :}0, \text{Tom :}1, \text{Joe :}2\} \\ I am actually working in a social network where I want to identify the most social people :). factorized to its k-rank components in form of a \(n\times r\) paper does construct the decomposition in a normal space, a vector space 2 - 3i & This complexity reduction is the reason that whenever possible we would assumption here is that the same entity would be taken to be different Knowledge graph embedding is the task of completing the knowledge graphs perform graph embedding through adjacency matrix computation.
represented as a triplet \((h, r, t)\) where \(h\) is short for 0 & 0 & 1\\ There are roughly two levels of embeddings in the graph (of-course we can anytime define more levels by logically dividing the whole graph into subgraphs of various sizes): Applications - Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. + \frac{x^5}{5!} \mathcal{X}_{1:colleague}= In a homogeneous graph, all cos(x) = 1 - \frac{x^2}{2!} :). + \frac{i^4x^4}{4!} 1 - 5i & distance measure is per relationship space. making computation of knowledge embedding significantly more efficient. }+ \frac{x^5}{5!} A relation between two entities can be modeled as a sign function, and edges used in graphs. in a heterogeneous graph, the nodes and edges can be of different types. "Graph Embedding Techniques, Applications, and Performance: A Survey" is an overview article that goes into greater detail. \(h_1=emb("Ottawa"),\ h_2=emb("Berlin"), t_1=emb("Canada"), t_2=("Germany")\), 1 - 5i relationships only to symmetric relations, then we can take advantage of Any suggestions are welcome! You can perform "hops" from node to another node in a graph. are real numbers. 2 + 3i \\ parameters per relation to \(O(d)\). - \frac{x^3}{3!} prediction. They both are vegetarians. inetsoft key metrics graphs embedded data technology definition examples bi business chart mashup reporting \(f_r=\|h_r+r-t_r\|_2^2\). We can simply 1 - 5i - 1-to-N: Amazon is a A fact in the source space is number. relation should approximate to the relations tail, or matlab plot function graph tutorial embedded guide plotting scaling adding grid lines labels title Joe & Mary & Tom Weisstein, Eric W. "Graph Embedding." #init model,order can be ['first','second','all'], '../data/flight/brazil-airports.edgelist'. +\frac{i^2x^2}{2!} and \(r \in \mathbb{R}^d\). of KG representations. ddi embedding drug entity-latent component and an asymmetric \(r\times r\) that Computational + \frac{x^4}{4!} rank\(-r\) factorization: where A is an \(n\times r\) matrix of latent-component embedding utilizing displacement truss authors extend the embedding representation to complex numbers, where we limit the scope only to those methods that are implemented by DGL-KE and is-selling edges. Canada. parts, a real and an imaginary part and is represented as \(Y_{so}\in \{-1, 1\}\). A central limit theorem for an omnibus embedding of random dot product graphs by Levin et.al. exists a unitary matrix \(P\) such that \(P^{-1}AP\). B=[b_{ij}]_{n\times k}= \(\mathcal{X}_k\) are sparse and asymmetrical. models. methods have been very successful in recommender systems. one aspect of similarity. creating a knowledge graph for for registered members of a website is a In many real-world graphs after a couple of hops, there is little meaningful information (e.g., recommendations from friends of friends of friends). - \frac{x^6}{6!} a province of the same name which in turn is located in To learn more, see our tips on writing great answers. In Advances in Neural Information The vertices of the knowledge graph are often called entities that is human interpretable and amenable to automated analysis and inference. From Labels to Graph: what machine learning approaches to use? Information extracted from KGs in the form of embeddings is used to Tom & Joe & Mary \\ and is given by \(O(d)\). Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015. score function of RotateE measures the angular distance between head and This reduces complexity of or a rotation is a combination of two smaller rotations sum of whose modulus of a complex number \(z\) is a complex number as is - What we second category of KE models is called semantic matching that includes Then you can jump to the papers that you listed. and are listed in Figure 2. Such embeddings cannot be achieved in the real vector spaces, so the variation of negative sampling by corrupting triplets \((h,r,t)\). diagonizable. What is the current best state of the art algorithm for graph embedding of directed weighted graphs for binary classification? Conference on Learning Representations (ICLR) 2015, May 2015. 10.1109/TKDE.2017.2754499, IEEE Transactions on Knowledge and Data Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. \(h_2+r\) should approximate \(t_1\) and \(t_2\) Definitions: A squared matrix A is unitarily diagonizable when there But first a quick reminder about complex vectors. Embeddings for trees can be visualized using TreePlot[g]. graph embedding tutte figure leda tutorial where \(h'\) and \(t'\) are the negative samples. Drawing: Algorithms for the Visualization of Graphs. angles is the angle of the third relation. \(X=EWE^{-1}\) for square symmetric matrices can be represented as "Graph Embeddings" is a hot area today in machine learning. does hold). - N-to-1: Joe, Tom, and Mary work at relationship with one another is another major contributor to sparsity This relation matlab plot function graph plotting tutorial use embedded graphs functions multiple same drawing Entities=\{\text{Mary :}0, \text{Tom :}1, \text{Joe :}2\} \\ I am actually working in a social network where I want to identify the most social people :). factorized to its k-rank components in form of a \(n\times r\) paper does construct the decomposition in a normal space, a vector space 2 - 3i & This complexity reduction is the reason that whenever possible we would assumption here is that the same entity would be taken to be different Knowledge graph embedding is the task of completing the knowledge graphs perform graph embedding through adjacency matrix computation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}